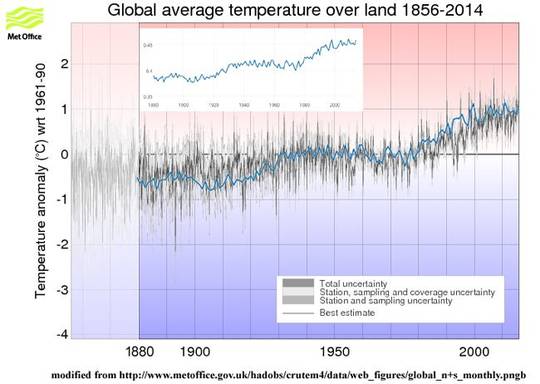
Chaosforscher Lorenz erneut bewiesen
Der Höhepunkt der Presseerklärung ist das Bild rechts mit der Original-Bildunterschrift:
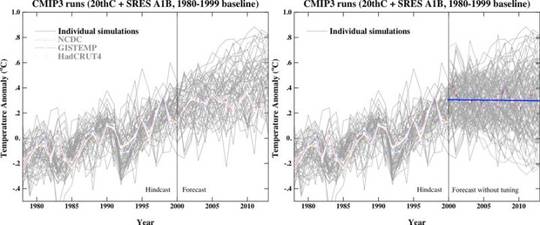
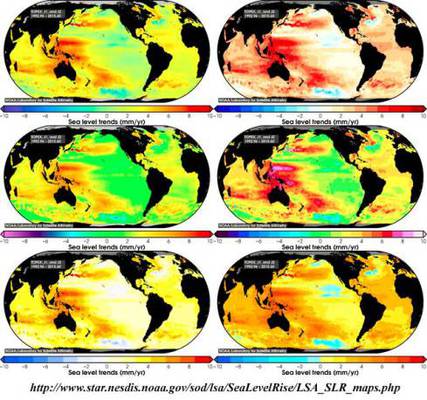
Trends der Wintertemperatur für Nordamerika zwischen 1963 und 2012 für jedes einzelne der 30 Mitglieder des CESM Large Ensemble. Die Variationen zwischen Erwärmung und Abkühlung in den 30 Membern illustrieren die weit reichenden Auswirkungen der natürlichen Variabilität, die dem vom Menschen verursachten Klimawandel überlagert sind. Das Ensemble-Mittel (EM; unten, zweites Bild von rechts) mittelt die natürliche Variabilität heraus, was allein den Erwärmungstrend zurücklässt, der dem vom Menschen verursachten Klimawandel zuzuordnen ist. Das Bild rechts unten (OBS) zeigt aktuelle Messungen aus dem gleichen Zeitraum. Vergleicht man das Ensemble Mean mit den Messungen, konnte das Wissenschaftlerteam aufgliedern, ein wie großer Anteil an der Erwärmung in Nordamerika der natürlichen Variabilität und welcher Anteil dem vom Menschen verursachten Klimawandel geschuldet ist. Die ganze Studie steht im American Meteorological Society’s Journal of Climate. (© 2016 AMS.)
Was ist das? Das Large Ensemble Community Project des UCAR hat eine Datengrundlage erzeugt von „30 Simulationen mit dem Community Earth System Model (CESM) mit einer Auflösung von 1° Länge/Breite. Jede einzelne Simulation erfährt ein identisches Szenario historischen Strahlungsantriebs, startet jedoch jeweils von einem etwas unterschiedlichen atmosphärischen Zustand“. Aber genau welche Art von „unterschiedlicher atmosphärischer Zustand“ ist gemeint? Wie unterschiedlich waren die Anfangsbedingungen? „Die Wissenschaftler modifizierten die Anfangsbedingungen des Modells leicht, indem sie die globale atmosphärische Temperatur um weniger als ein Billionstel Grad variierten“.
Die Bilder, Nummern 1 bis 30, repräsentieren jeweils die Ergebnisse eines Einzellaufes des CESM mit einheitlichen, sich um ein Billionstel Grad unterscheidenden Anfangstemperatur – jede einzelne eine Projektion der Wintertemperaturtrends in Nordamerika im Zeitraum 1963 bis 2012. Das Bild rechts unten mit der Bezeichnung OBS zeigt die tatsächlich beobachteten Trends.
Es gibt eine Studie, aus der dieses Bild stammt: Forced and Internal Components of Winter Air Temperature Trends over North America during the past 50 Years: Mechanisms and Implications. Dabei handelt es sich um eine Studie, die lediglich eine von „etwa 100 begutachteten Artikeln in wissenschaftlichen Journalen ist, welche Daten des CESM Large Ensemble herangezogen hatten“. Ich werde diese Studie nicht kommentieren, sehr wohl aber das Bild, dessen Bildunterschrift sowie die Statements in der Presseerklärung selbst.
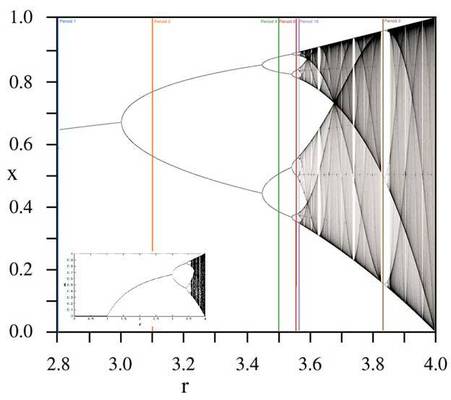
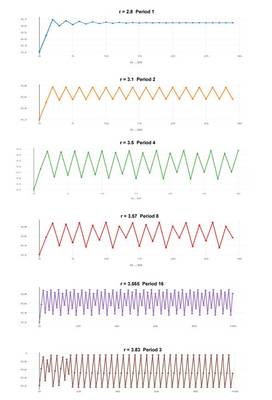
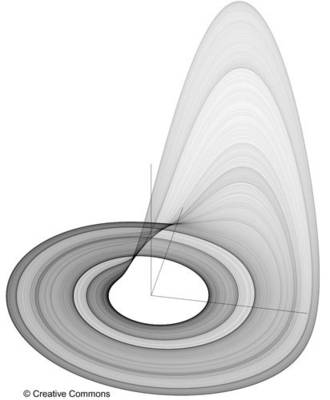
Ich bekenne verblüfft zu sein – nicht durch die Tatsache, dass 30 CESM-Modellläufe 30 vollkommen unterschiedliche 50-Jahre-Klimaprojektionen aus nahezu identischen Ausgangsbedingungen erzeugt haben. Das war absolut zu erwarten. Tatsächlich zeigte dies schon Edward Lorenz mit seinen Spielzeug-Wettermodellen auf seinem (verglichen mit heutigen Standards) „Spielzeug“-Computer in den sechziger Jahren. Seine Entdeckungen führten zu einem Studienbereich, der heute als Chaos-Theorie bekannt ist, also die Untersuchung nichtlinearer dynamischer Systeme, vor allem solcher, die hoch sensitiv bzgl. ihrer Ausgangsbedingungen sind. Unsere 30 CESM-Läufe wurden initialisiert mit einem Unterschied von – was? Ein Billionstel Grad beim Anfangswert der globalen atmosphärischen Temperatur – ein so geringer Betrag, dass er buchstäblich von modernen Thermometern unmessbar ist. Lässt man die Simulationen gerade mal über 50 Jahre laufen – von 1963 bis 2012 – ergeben sich Resultate vollständig den Ergebnissen von Lorenz zufolge: „Zwei Zustände, die sich nicht wahrnehmbar unterscheiden, können bei der Simulation eventuell zwei Zustände herauskommen, die sich erkennbar unterscheiden … Falls es dann zu irgendeinem Fehler welcher Art auch immer kommt bei der Messung des Ist-Zustandes – und in jedwedem realen System sind derartige Fehler unvermeidlich – kann eine akzeptable Vorhersage eines unmittelbaren Zustandes in ferner Zukunft sehr gut unmöglich sein … Angesichts der unvermeidlichen Ungenauigkeit und der Unvollständigkeit von Wetterbeobachtungen wären präzise langfristige Vorhersagen nicht existent“.
Worin liegt die Bedeutung von Lorenz? Von buchstäblich ALLEN unserer Daten der historischen „globalen atmosphärischen Temperatur“ weiß man, dass sie um mindestens ±0,1°C ungenau sind. Egal welcher Initialwert die engagierten Leute am NCAR/UCAR in das CESM als globale atmosphärische Temperatur eingeben, es wird sich von der Realität um viel, viel mehr Größenordnungen unterscheiden als der Temperaturunterschied von 1 Billionstel Grad bei der Initialisierung dieser 30 CESM-Läufe ausmacht. Spielt das wirklich eine Rolle? Meiner Ansicht nach spielt es keine Rolle. Man kann leicht erkennen, dass die kleinsten aller Unterschiede, selbst bei einem einzelnen Initialwert, zu 50-Jahre-Projektionen führen, die sich so stark voneinander unterscheiden wie nur irgend möglich (siehe Fußnote 1 unten). Ich weiß nicht, wie viele Initialbedingungen in das CESM eingehen müssen, um es zu initialisieren – aber es ist sicher mehr als nur eine. Um wieviel mehr würden sich die Projektionen unterscheiden, falls jeder der Initialwerte verändert werden würde, selbst wenn auch nur leicht?
Was mich verblüfft ist die in der Bildunterschrift enthaltene Behauptung: „Das Ensemble-Mittel (EM; unten, zweites Bild von rechts) mittelt die natürliche Variabilität heraus, was allein den Erwärmungstrend zurücklässt, der dem vom Menschen verursachten Klimawandel zuzuordnen ist“.
In der Studie, die zur Erstellung dieser Graphik geführt hat, lautet die präzise Behauptung:
Dieser Rahmen der Modellierung enthält 30 Simulationen des Community Earth System Model (CESM) mit einer Auflösung von 1° Länge/Breite, von denen jede Einzelne ein identisches Szenario des historischen Strahlungsantriebs erfährt, aber mit einem leicht unterschiedlichen atmosphärischen Anfangszustand. Folglich resultiert jedweder Spread innerhalb der Ensemble-Ergebnisse aus der unvorhersagbaren internen Variabilität, die sich dem erzwungenen Klimawandel-Signal überlagert.
Dieser Gedanke ist sehr verführerisch. Oh wie schön es wäre, wenn das stimmen würde – falls es wirklich so einfach wäre.
Aber so einfach ist es nicht. Und meiner Überzeugung nach ist er fast mit Sicherheit falsch.
Das Klimasystem ist ein gekoppeltes, nichtlineares und chaotisches dynamisches System – wobei die beiden gekoppelten Hauptsysteme die Atmosphäre einerseits und die Ozeane andererseits sind. Diese beiden sich ungleich erwärmenden Systeme agieren unter dem Einfluss der Gravitationskräfte von Erde, Mond und Sonne, während sich der Planet im All dreht und einem ungleichmäßigen Orbit um die Sonne folgt. Dies erzeugt ein kombiniertes dynamisches System unglaublicher Komplexität, welches die erwarteten Typen chaotischer Phänomene zeigt, die von der Chaos-Theorie vorhergesagt werden – wobei ein Aspekt dieser Theorie eine ausgeprägte Abhängigkeit von den Anfangsbedingungen ist. Wenn ein solches System mathematisch modelliert wird, ist es unmöglich, alle Nichtlinearitäten zu eliminieren (vielmehr ist es so, dass ein Modell umso ungültiger ist, je mehr die nichtlinearen Formeln vereinfacht werden).
Die Mittelung von 30 Ergebnissen, die durch das mathematisch chaotische Verhalten jedweden dynamischen Systems erzeugt werden, „mittelt die natürliche Variabilität NICHT heraus“ in dem modellierten System. Die Mittelung bringt nicht einmal auch nur ansatzweise Derartiges zustande. Die Mittelung von 30 chaotischen Ergebnissen erzeugt lediglich das „Mittel jener speziellen 30 chaotischen Ergebnisse“.
Warum wird mit der Mittelung die natürliche Variabilität herausgemittelt? Weil es einen gewaltigen Unterschied gibt zwischen Zufalls-Systemen und chaotischen Systemen. Diesen Unterschied scheint man bei der Aufstellung der obigen Behauptung übersehen zu haben.
Das Werfen einer Münze (mit einer nicht gezinkten Münze) ergibt Zufallsergebnisse – nicht Kopf-Zahl-Kopf-Zahl. Wenn man die Münze oft genug geworfen hat, ist es möglich, die Zufälligkeit herauszumitteln und zu einem wahren Verhältnis möglicher Ergebnisse zu kommen – welches 50 zu 50 für Kopf-Zahl sein wird.
[Anders gesagt: Hier wird der in der Tat gravierende Unterschied angesprochen zwischen deterministischem Chaos {Klima, Wetter} und dem absoluten Chaos {Würfel, Münzwurf}. Anm. d. Übers.]
Dies gilt nicht für chaotische Systeme. In chaotischen Systemen scheinen die Ergebnisse nur zufällig zu sein – aber sie sind in keiner Weise zufällig – sie sind durchweg deterministisch, wobei jeder nachfolgende Zustand präzise bestimmt wird durch die Anwendung einer speziellen Formel auf den bestehenden Wert, was man dann bei dem folgenden Wert wiederholt. Bei jedem Wechsel kann der nächste Wert exakt berechnet werden. Was man in einem chaotischen System nicht tun kann, ist vorherzusagen, welcher Wert nach den nächsten 20 Wechseln auftreten wird. Man muss sich durch jeden einzelnen der 19 Schritte zuvor hindurch rechnen, um dorthin zu kommen.
In chaotischen Systemen haben diese Nicht-Zufalls-Ergebnisse – obwohl sie zufällig aussehen können – Ordnung und Struktur. Jedes chaotische System weist Regimes der Stabilität, Periodizität, Perioden-Verdoppelung auf, welche nach Zufall aussehen, aber im Wert abhängig sind. In einigen Fällen treten auch Regimes auf, die hoch geordnet in etwas sind, was man „Fremd-Attraktoren“ [strange attractors] nennt. Einige dieser Zustände, dieser Regimes, sind Gegenstand statistischer Analysen und können als „glatt“ [smooth] angesehen werden (Regionen, die statistisch gleichmäßig daherkommen) – andere variieren phantastisch, wunderschön anzusehen im Phasenraum [phase space], und ausgeprägt „un-glatt“ [un-smooth], wobei einige Regionen vor Aktivität strotzen, während andere kaum angesprochen werden und die zutiefst widerstandsfähig sind gegen einfache statistische Analyse – obwohl es ein Studienbereich in der Statistik gibt, der sich auf dieses Problem konzentriert. Dies involviert jedoch nicht die Art des Mittels, das in diesem Falle herangezogen wird.
Die Ergebnisse chaotischer Systeme können folglich nicht einfach gemittelt werden, um Zufälligkeit oder Variabilität herauszumitteln – die Ergebnisse sind nicht zufällig und nicht notwendigerweise gleich variabel. In unserem Fall haben wir absolut keine Ahnung bzgl. Gleichheit und Glätte des realen Klimasystems.
Auf einem grundlegenderen Niveau wäre die Mittelung von 30 Ergebnissen nicht einmal gültig für ein echt zufälliges Zwei-Werte-System wie dem Werfen einer Münze oder ein Sechs-Werte-System beim Werfen eines einzigen Würfels. Dies ist für jeden Statistik-Student im ersten Semester offensichtlich. Vielleicht ist es die nahezu unendliche Anzahl möglicher chaotischer Ergebnisse des Klimamodells, welche es so aussehen lässt, als ob ein gleichmäßiger Spread von Zufallsergebnissen vorliegt, der es dem Anfänger erlaubt, diese Regel zu ignorieren.
Hätten sie das Modell 30 oder 100 mal mehr laufen lassen und unterschiedliche Ausgangsbedingungen adjustiert, würden sie potentiell einen vollkommen unterschiedlichen Satz von Ergebnissen bekommen – vielleicht eine Kleine Eiszeit in einigen Läufen – und sie hätten ein unterschiedliches Mittel. Würde man von diesem neuen, unterschiedlichen Mittel auch sagen, dass es ein Ergebnis repräsentiert, welches „die natürliche Variabilität herausmittelt, was allein den Erwärmungstrend zurücklässt, der dem vom Menschen verursachten Klimawandel zuzuordnen ist“? Wie viele unterschiedliche Mittelwerte könnten auf diese Art und Weise erzeugt werden? Ich habe den Verdacht, dass sie nichts anderes repräsentieren würden als das Mittel aller möglichen Klima-Outputs dieses Modells.
Das Modell hat von Anfang an nicht wirklich irgendeine „natürliche Variabilität“ – es gibt keine Formel in dem Modell, von der man sagen kann, dass sie jenen Part des Klimasystems repräsentiert, der „natürliche Variabilität“ ist – was das Modell hat, sind mathematische Formeln, die vereinfachte Versionen der nichtlinearen mathematischen Formeln sind, die Dinge repräsentieren wie den Nicht-Gleichgewichts-Wärmetransfer [non-equilibrium heat transfer], den dynamischen Fluss ungleichmäßig erwärmter Flussobjekte, konvektive Abkühlung, Flüsse aller Arten (Ozeane und Atmosphäre), von deren Dynamik man weiß, dass sie in der realen Welt chaotisch sind. Die mathematisch chaotischen Ergebnisse spiegeln das, was wir als „natürliche Variabilität“ kennen – wobei dieser Terminus nur Gründe nichtmenschlicher Natur meint – und sind in das Modell als solches eingebaut. Die chaotischen Klima-Ergebnisse der realen Welt, welche die wahre natürliche Variation sind, verdanken ihre Existenz den gleichen Prinzipien – der Nichtlinearität dynamischer Systeme – aber die in der realen Welt agierenden dynamischen Systeme, in denen die natürliche Variabilität nicht nur jene in das Modell eingebaute „Natürlichkeit“ enthält, sondern auch alle jene Ursachen, die wir nicht verstehen, sowie jene, die uns nicht bewusst sind. Es wäre ein Fehler, die beiden unterschiedlichen Variabilitäten als eine Identität anzusehen – ein und dasselbe.
Folglich kann man nicht sagen, dass „jedweder Spread im Ensemble“ die Folge der internen Variabilität des Klimasystems ist oder jenen als buchstäblich die „natürliche Variabilität“ repräsentierend ansehen, und zwar in dem Sinne, in dem dies in der Klimawissenschaft allgemein genannt wird. Der Spread im Ensemble resultiert einfach aus dem mathematischen Chaos, das inhärent in den Formeln steckt, die im Klimamodell gerechnet werden. Er repräsentiert lediglich den Spread, den erzwungene Struktur und die Parametrisierung des Modells selbst.
Man erinnere sich, jedes der 30 Bilder aus den 30 Modellläufen des CESM sind durch einen identischen Code erzeugt worden, identische Parameter, identische Antriebe – aber unter alles andere als identischen Ausgangsbedingungen. Und doch passt keines der Ergebnisse zum beobachteten Klima des Jahres 2012. Nur eines kommt diesem halbwegs nahe. Niemand glaubt, dass diese tatsächliche Klimazustände repräsentieren. Ein volles Drittel der Läufe erzeugt Projektionen, die wenn sie für 2012 passend gewesen wären, die Klimawissenschaft auf den Kopf gestellt hätten. Wie können wir dann annehmen, dass die Mittelung dieser 30 Klimazustände auf magische Weise irgendwie das reale Klima repräsentieren kann mit der herausgemittelten natürlichen Variabilität? Dies sagt uns in Wirklichkeit nur, wie ausgesprochen empfindlich das CESM gegenüber den Ausgangsbedingungen ist. Und es sagt uns etwas über die Grenzen projizierter Klimazustände, die das modellierte System zulassen kann. Was wir im Ensemble-Mittel und Spread sehen, ist lediglich das Mittel jener exakten Läufe und deren Spread über einen 50-jährigen Zeitraum. Aber es hat kaum etwas zu tun mit dem realen Weltklima.
Die mathematisch chaotischen Ergebnisse des modellierten dynamischen Systems mit der „natürlichen Variabilität“ der realen Welt – die Behauptung, dass beides ein und dasselbe ist – ist eine Hypothese ohne Grundlage, vor allem dann, wenn man die Klimaauswirkungen in ein Zwei-Werte-System aufteilt, das einzig die „natürliche Variabilität“ und den „vom Menschen verursachten Klimawandel“ enthält.
Die Hypothese, dass die Mittelung von 30 chaotisch erzeugten Klimaprojektionen ein Ensemble Mean erzeugt, folgt mit Sicherheit nicht aus einem Verständnis der Chaos-Theorie. Zumindest wenn dieses Ensemble Mean die natürliche Variabilität auf eine Art und Weise herausgemittelt hat, dass der Vergleich der EM-Projektion mit den tatsächlich gemessenen Daten erlaubt „zu zergliedern, wie viel der Erwärmung in Nordamerika der natürlichen Variabilität und wie viel davon dem vom Menschen verursachten Klimawandel“ geschuldet ist.
Das Zwei-Werte-System (natürliche Variabilität vs. vom Menschen verursacht) ist nicht ausreichend. Weil wir keine adäquaten Kenntnisse darüber haben, welche alle diese natürlichen Gründe sind (auch nicht über die wahre Größenordnung ihrer Auswirkungen), können wir sie nicht von all den menschlichen Gründen trennen – wir können noch nicht Ausmaße von Auswirkungen abgrenzen wegen der „natürlichen“ Gründe, und folglich können wir auch nicht den „vom Menschen verursachten Rest“ berechnen. Wie auch immer, vergleicht man das Ensemble Mean vieler nahezu identischer Läufe eines modellierten, bekannt chaotischen Systems mit den Beobachtungen der realen Welt, ist dies kein mathematisch oder wissenschaftlich gestütztes Verfahren im Lichte der Chaos-Theorie.
Im Klima-System gibt es bekannte Ursachen, und es verbleibt die Möglichkeit unbekannter Ursachen. Der Vollständigkeit halber sollten wir bekannte Unbekannte erwähnen – wie etwa Wolken sowohl Auswirkung als auch Ursache sind. In unbekannten Beziehungen – und unbekannten Unbekannten – mag es Ursachen für klimatische Änderungen geben, die uns bislang nicht einmal andeutungsweise bekannt sind, obwohl die Möglichkeit bedeutsamer „Großer-Roter-Knopf“-Ursachen des verbleibenden Unbekannten von Jahr zu Jahr abnehmen. Und doch, weil das Klimasystem ein gekoppeltes, nichtlineares System ist – chaotisch in seiner ureigenen Natur – ist das Auseinanderfieseln der gekoppelten Ursachen und Auswirkungen ein laufendes Projekt und wird es auch noch lange bleiben.
Man beachte auch, dass weil das Klimasystem seiner Natur nach ein eingezwängtes [constrained] chaotisches System ist (siehe Anmerkung 2), wie diese Studie zu zeigen versucht, kann es einige Klima-Ursachen geben, welche – obwohl sie so klein sind wie „eine Änderung der globalen atmosphärischen Temperatur um ein Billionstel Grad“ – zukünftig Klimaänderungen auslösen können, die viel, viel größer sind als wir uns vorstellen können.
Was das vom NCAR/UCAR Large Ensemble Community Project erzeugte Image tatsächlich bewirkt, ist die totale Validierung der Entdeckung von Edward Lorenz, dass Modelle von Wetter- und Klimasystemen ihrer ureigenen Natur nach chaotisch sind und unabdingbar sein müssen – ausgesprochen empfindlich gegenüber Anfangsbedingungen – und sich daher Versuchen einer „präzisen Langfristvorhersage“ entziehen.
——————————————————-
Anmerkungen:
1. Klimamodelle sind so parametrisiert, das sie erwartete Ergebnisse erzeugen. Beispiel: Falls ein Modell allgemein keine Ergebnisse erzeugen kann, die aktuelle Beobachtungen spiegeln, wenn man sie zur Projektion bekannter Daten heranzieht, dann muss es solange adjustiert werden, bis das doch der Fall ist. Es ist offensichtlich: falls ein Modelllauf im Jahre 1900 startet und über 100 Jahre projiziert und sich dabei eine Kleine Eiszeit bis zum Jahr 2000 ergibt, dann muss man davon ausgehen, dass irgendetwas in dem Modell fehlt. Dieser Gedanke ist berechtigt, obwohl es zunehmende Beweise gibt, dass die spezifische Praxis ein Faktor sein kann für die Unfähigkeit der Modelle, selbst kurzfristige Zukunft (Dekaden) korrekt zu projizieren, und für deren unverändertes Erzeugen von Erwärmungsraten weit oberhalb der gemessenen Raten.
2. Ich beziehe mich auf das Klimasystem als „eingezwängt“ allein auf der Grundlage unseres langfristigen Verständnisses des Klimas der Erde – Temperaturen verharren in einem relativ engen Band, und größere Klimazustände scheinen auf Eiszeiten und Zwischeneiszeiten beschränkt zu sein. Genauso in der Chaos-Theorie – Systeme sind bekannt eingezwängt durch Faktoren innerhalb des Systems selbst – obwohl sich die Ergebnisse als chaotisch erweisen können, sind sie nicht „bloß irgendetwas“, sondern ereignen sich innerhalb definierter mathematischer Räume – von denen einige phantastisch kompliziert sind.
Link: https://judithcurry.com/2016/10/05/lorenz-validated/
Übersetzt von Chris Frey EIKE