
Ich erwiderte:
Brandon, FALLS es eine solche Beschleunigung gibt, ist sie vernachlässigbar gering. Ich kann nirgendwo einen statistisch signifikanten Beweis dafür finden, dass er real ist. Allerdings „leugne“ ich überhaupt nichts*. Ich stehe lediglich nicht hinter den entsprechenden Statistiken.
[*Eschenbach drückt sich im Original etwas drastischer aus. Anm. d. Übers.]
Brandon antwortete:
,Falls es eine solche Beschleunigung gibt‘: Es gibt sie, Willis! Und ich zeige es dir gleich. – ,sie ist vernachlässigbar gering‘ Wenn du ein besseres Modell hast, wie das Klima abläuft, dann kannst du mit mir über relative Größenordnungen von Auswirkungen sprechen.
Brandon unterstrich seine nicht gestützten Behauptungen mit der folgenden Graphik der Lufttemperatur, wobei ich nicht so genau weiß warum … ich glaube, er griff hastig nach der erstbesten Graphik und verwechselte diese mit Meeresspiegel.
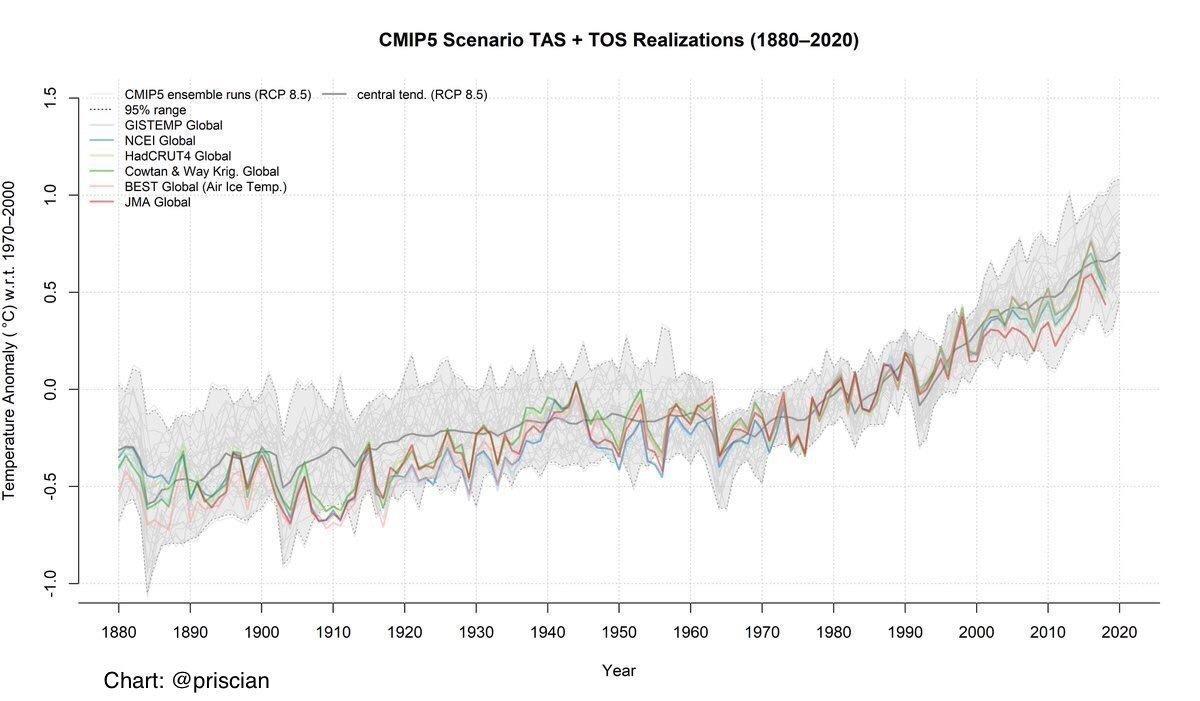
Nun habe ich kürzlich einen Beitrag zum Anstieg des Meeresspiegels geschrieben mit dem Titel „Inside The Acceleration Factory” [etwa: innerhalb der Beschleunigungs-Maschinerie]. Allerdings geht das Problem hinsichtlich von Behauptungen über den Meeresspiegel tiefer. Es besteht darin, dass die entsprechenden Daten in sehr hohem Maße autokorreliert sind.
„Autokorreliert“ im Zusammenhang mit einer Zeitreihe wie Meeresspiegel oder Temperatur bedeutet, dass die Gegenwart mit der Vergangenheit korreliert ist. Mit anderen Worten, Autokorrelation bedeutet, dass heiße Tage wahrscheinlicher heiße Tagen als kühle Tagen folgen, und umgekehrt. Gleiches gilt für warme und kalte Monate oder warme und kalte Jahre. Erstreckt sich eine solche Autokorrelation über lange Zeiträume, Jahre oder Jahrzehnte, nennt man das oft „langzeitliche Persistenz“ oder LTP.
Und Trends sind sehr verbreitet in LTP zeigenden Datensätzen. Eine andere Art, dies zu beschreiben, findet sich in einem Beitrag im Magazin Nature aus dem Jahr 2005 mit dem Titel „Nature’s Style: Naturally trendy“. Das kommt ziemlich genau hin. Natürliche Datensätze neigen dazu, Trends verschiedener Länge und Stärke zu zeigen aufgrund von LTP.
Und diese langzeitliche Persistenz LTP führt zu großen Problemen, wenn man zu bestimmen versucht, ob der Trend in einer gegebenen Zeitreihe statistisch signifikant ist oder nicht. Um dies zu erläutern, möchte ich das Abstract von „Naturally Trendy“ diskutieren. Die Ausschnitte daraus sind kursiv gesetzt. Es beginnt so:
Hydroklimatologische Zeitreihen zeigen oftmals Trends.
Stimmt. Zeitreihen von Durchflussmenge in Flüssen, Regenmenge, Temperatur und so weiter haben Trends.
Während die Größenordnung von Trends ziemlich genau bestimmt werden kann, ist die korrespondierende statistische Signifikanz, welche manchmal zur Untermauerung wissenschaftlicher oder politischer Argumente herangezogen wird, weniger sicher, weil die Signifikanz entscheidend abhängt von der Null-Hypothese, welche wiederum subjektive Dinge reflektiert darüber, was man zu sehen erwartet.
Halten wir hier mal kurz an. Über jedwedes vorgegebene Zeitintervall befindet sich jede wetterbezogene Zeitreihe, sei das nun Temperatur, Regenmenge oder welche Variable auch immer, in einem von zwei Zuständen:
Aufwärts oder
Abwärts.
Die relevante Frage für einen gegebenen Wetter-Datensatz lautet also niemals „zeigt sich ein Trend?“. Der zeigt sich immer, und wir können dessen Größe messen.
Die relevante Frage lautet vielmehr: ist ein vorhandener Trend ein UNGEWÖHNLICHER Trend oder spiegelt er einfach nur die natürliche Variation?
Nun haben wir Menschen einen gesamten großen Bereich der Mathematik erstellt, genannt „Statistik“, um genau diese Frage zu beantworten. Wir sind Spekulanten, und wir wollen die Möglichkeiten ausloten.
Allerdings stellt sich dann heraus, dass die Frage nach der Ungewöhnlichkeit eines Trends etwas komplizierter ist. Die wirkliche Frage lautet: ist der Trend UNGEWÖHNLICH – im Vergleich zu wem oder was?
Die gute alte mathematische Statistik beantwortet die folgende Frage: ist der Trend UNGEWÖHNLICH im Vergleich zu Zufallsdaten? Und das ist eine sehr nützliche Frage. Sie ist auch sehr genau für wirkliche Zufalls-Spielerchen wie etwa würfeln. Nehme ich einen Würfelbecher mit zehn Würfeln darin und bekomme beim Würfeln zehnmal die Augenzahl drei, würde ich sonstwas darauf wetten, dass die Würfel gezinkt sind.
ALLERDINGS – und das ist ein sehr großes allerdings – wie sieht es aus, wenn die Frage lautet, ob ein gegebener Trend ungewöhnlich nicht im Vergleich zu einer Zufalls-Zeitreihe ist, sondern zu einer autokorrelierten zufälligen Zeitreihe ist? Und im Besonderen, ist ein gegebener Trend ungewöhnlich im Vergleich zu einer Zeitreihe mit langzeitlicher Persistenz (LTP)? Sie fahren in ihrem Abstract fort:
Wir betrachten statistische Trends hydroklimatologischer Daten beim Vorhandensein von LTP.
Sie führen eine Reihe von Trend-Tests durch, um herauszufinden, wie gut diese sich im Vergleich zu Zufalls-Datensätzen mit LTP machen.
Monte Carlo-Experimente mit FARIMA-Modellen zeigen, dass Trend-Tests ohne Berücksichtigung von LTP die statistische Signifikanz beobachteter Trends mit LTP erheblich überschätzen.
Einfach gesagt, reguläre statistische Tests, die LTP nicht berücksichtigen, zeigen fälschlich signifikante Trends, obwohl diese in Wirklichkeit einfach nur natürliche Variationen sind. Im Hauptteil der Studie liest man dazu:
Noch wichtiger ist, wie Mandelbrot und Wallis (1969b, S. 230-231) beobachteten, „eine wahrnehmbare markante Charakteristik fraktionalen Rauschens ist, dass deren Beispielfunktionen eine erstaunliche Vielfalt von ,Besonderheiten‘ aller Art zeigen, einschließlich Trends und zyklischer Schwingungen mit unterschiedlichen Frequenzen“. Man kann sich leicht vorstellen, dass LTP verwechselt werden kann mit Trend.
Das ist eine sehr wichtige Beobachtung. „Fraktionales Rauschen“, also Rauschen mit LTP, enthält eine Vielfalt von Trends und Zyklen, die natürlich und im Rauschen inhärent sind. Aber diese Trends und Zyklen haben keinerlei Bedeutung für irgendetwas. Sie tauchen auf, dauern eine Weile an und verschwinden wieder. Es sind keine fixierten Trends oder permanente Trends. Sie sind die Folge der LTP und nicht extern angetrieben. Sie sind auch nicht diagnostisch – man kann nicht davon ausgehen, dass die Gegenwart von etwas, das wie ein 20-Jahre-Zyklus aussieht, ein konstantes Merkmal der Daten ist, und er kann auch nicht herangezogen werden als ein Mittel zur Vorhersage der Zukunft. Er könnte einfach ein Teil von Mandelbrots „erstaunlicher Vielfalt von Besonderheiten“ sein.
Der gebräuchlichste Weg, mit LTP umzugehen, ist der Gebrauch von etwas, was „effektives N“ genannt wird. In der Statistik „repräsentiert N die Anzahl der Datenpunkte. Haben wir also z. B. zehn Jahre mit monatlichen Datenpunkten, heißt das N = 120. Je mehr Datenpunkte man hat, desto stärker im Allgemeinen die statistischen Schlussfolgerungen … aber wenn LTP präsent ist, wird die statistische Signifikanz erheblich überschätzt. Und mit „erheblich“ kann mit regulären statistischen Verfahren leicht eine Überschätzung der Signifikanz um 25 Größenordnungen herauskommen …
Ein allgemeines Verfahren zur Berücksichtigung dieses Problems ist die Berechnung der Signifikanz derart, als ob es sich um eine viel kleinere Anzahl von Datenpunkten handelt, also ein kleineres „effektives N“. Dann führen wir die regulären statistischen Tests noch einmal durch.
Ich selbst verwende jetzt das Verfahren von Koutsoyiannis, um das „effektive N“ zu berechnen. Das hat mehrere Gründe.
Erstens, man kann es mathematisch aus bekannten Grundsätzen ableiten.
Zweitens, es ist abhängig von genau gemessenen Persistenz-Charakteristika des analysierten Datensatzes, sowohl lang- als auch kurzfristig.
Drittens, wie im Link oben schon diskutiert, war das von mir unabhängig davon entwickelte Verfahren zu diesem Zweck genau das, welches Demetris Kousoyannis schon gefunden hatte. Er wird oft erwähnt in der Studie „Naturally Trendy“.
Damit als Prolog komme ich jetzt zurück zur Frage nach dem Anstieg des Meeresspiegels. Es gibt ein paar Rekonstruktionen dieses Anstiegs. Die grundlegendsten davon stammen von Jevrejeva sowie Church und White und auch aus den TOPEX/JASON-Daten. Hier folgt eine Graphik aus dem oben erwähnten Beitrag. Sie zeigt die Daten von Tiden-Messpunkten nach Church und White:
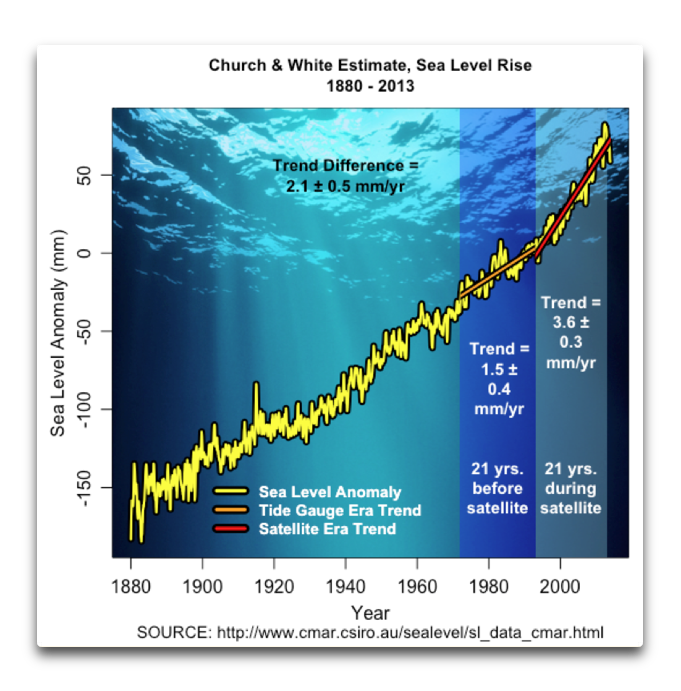
Nun habe ich in meinem anderen Beitrag schon darauf hingewiesen, dass sich … komischerweise … mit genau dem gleichen Startpunkt wie die Satelliten-Aufzeichnungen, also 1992, der Trend in den Tiden-Daten von Church und White mehr als verdoppelt hat.
Und während diese Änderung des Trends an sich schon bedenklich ist, gibt es ein noch größeres Problem. Das zuvor erwähnte „effektive N“ ist eine Funktion von etwas, das man den „Hurst-Exponenten“ nennt. Der Hurst-Exponent ist eine Zahl zwischen Null und +1, welche die Größe der LTP anzeigt. Ein Wert von ein-halb bedeutet keine LTP. Hurst-Exponenten von Null bis ein-halb zeigen negative LTP (Wärme gefolgt von Kälte usw.) und Werte über ein-halb zeigen die Existenz von LTP (warm gefolgt von warm usw.) Je näher der Hurst-Exponent bei 1 liegt, umso mehr LTP zeigt sich in dem Datensatz.
Und wie groß ist nun der Hurst-Exponent im oben gezeigten Datensatz von Church und White? Nun, er beträgt 0,93, also fast schon 1 … ein sehr, sehr hoher Wert. Teilweise schreibe ich dies der Tatsache zu, dass jedwede globale Rekonstruktion das Mittel aus Aberhunderten Tiden-Aufzeichnungen ist. Führt man eine großräumige Mittelung durch, kann die LTP im resultierenden Datensatz verstärkt werden.
Und wie groß ist nun das effektive N, also die effektive Anzahl von Datenpunkten, in den Daten von Church und White? Beginnen wir mit „N“, also der tatsächlichen Anzahl der Datenpunkte (in unserem Fall hier Monate). In den Meeresspiegel-Daten von C&W umfasst die Anzahl der Datenpunkte 1608 Monate mit Daten, also N = 1608.
Weiter, das effektive N (normalerweise abgekürt als „Neff“) ist gleich:
N (Anzahl der Datenpunkte) hoch 2*(1 – Hurst-Exponent))
Und 2* (1 – Hurst-Exponent) ist gleich 0,137. Daraus folgt:
Neff = N(2 * (1 – Hurst-Exponent)) = 16080,137 = 2,74
Mit anderen Worten, die C&W-Daten enthalten so viel LTP, dass sie sich im Endeffekt so verhalten, als ob es nur drei Datenpunkte gäbe.
Reichen nun diese drei Datenpunkte aus, um einen Trend in den Daten bzgl. Meeresspiegel zu finden? Nun, fast, aber nicht ganz. Mit einem effektiven N von drei beträgt der p-Wert des Trends in den C&W-Daten 0,07. Dies liegt etwas oberhalb dessen, was in der Klimawissenschaft als statistisch signifikant gilt; das ist ab einem Wert von 0,05 der Fall. Und hätte man ein effektives N von vier anstatt von drei, wäre es tatsächlich statistisch signifikant mit einem p-Wert kleiner als 0,05.
Hat man jedoch nur drei Datenpunkte, reicht das noch nicht einmal aus, um zu erkennen, ob die Ergebnisse verbessert werden durch Hinzufügen eines Beschleunigungs-Terms in die Gleichung. Das Problem hierbei ist, dass man mit einer zusätzlichen Variable jetzt drei regelbare Parameter für die Berechnung kleinster Quadrate hat bei nur drei Datenpunkten. Dies bedeutet, dass man Null Freiheitsgrade hat … das funktioniert nicht.
„Leugne“ ich also, dass sich der Meeresspiegel-Anstieg auf signifikante Weise verstärkt?
Aber nein, ich leugne gar nichts. Stattdessen sage ich, dass wir nicht über die Daten verfügen, die wir brauchen, um die Frage zu beantworten, ob sich der Anstieg beschleunigt.
Gibt eine Lösung für das LTP-Problem in den Datensätzen? Nun, ja und nein. Es gibt in der Tat Lösungen, aber den Klimawissenschaftlern scheint es vorbestimmt, diese zu ignorieren. Ich kann nur vermuten, dass der Grund hierfür darin zu suchen ist, dass viele Behauptungen bzgl. signifikanter Ergebnisse zurückgezogen werden müssten, falls man die statistische Signifikanz korrekt berechnen würde. Noch einmal zu der Studie „Nature’s Style: Naturally Trendy“:
In jedem Falle gibt es aussagekräftige Trend-Tests zur Bestimmung der LTP.
Es ist daher überraschend, dass in fast jeder Abschätzung einer Trend-Signifikanz bei geophysikalischen Variablen während der letzten paar Jahrzehnte eine angemessene Berücksichtigung der LTP nicht vorhanden ist.
In der Tat, das ist überraschend, besonders wenn man sich in Erinnerung ruft, dass die Studie Naturally Trendy bereits vor 14 Jahren veröffentlicht worden ist … und die Lage hat sich seitdem nicht verbessert. LTP wird nach wie vor nicht angemessen berücksichtigt.
Noch einmal zu der Studie:
Diese Ergebnisse haben Implikationen sowohl für die Wissenschaft als auch für die Politik.
Beispiel: Hinsichtlich der Temperaturdaten gibt es überwältigende Beweise, dass sich der Planet über das vorige Jahrhundert erwärmt hat. Aber ist diese Erwärmung der natürlichen Dynamik geschuldet? Angesichts dessen, was wir über die Komplexität, langzeitlicher Persistenz und Nicht-Linearität des Klimasystems wissen, scheint die Antwort Ja! zu sein.
Ich bin sicher, dass man die Probleme sieht, welche eine derartige statistische Ehrlichkeit einem viel zu großen Teil der Mainstream-Klimawissenschaft bereitet …
Link: https://wattsupwiththat.com/2019/02/20/sea-level-and-effective-n/
Übersetzt von Chris Frey EIKE














{kind=link}
Wir freuen uns über Ihren Kommentar, bitten aber folgende Regeln zu beachten:
- Bitte geben Sie Ihren Namen an (Benutzerprofil) - Kommentare "von anonym" werden gelöscht.
- Vermeiden Sie Allgemeinplätze, Beleidigungen oder Fäkal- Sprache, es sei denn, dass sie in einem notwendigen Zitat enthalten oder für die Anmerkung wichtig sind. Vermeiden Sie Schmähreden, andauernde Wiederholungen und jede Form von Mißachtung von Gegnern. Auch lange Präsentationen von Amateur-Theorien bitten wir zu vermeiden.
- Bleiben Sie beim Thema des zu kommentierenden Beitrags. Gehen Sie in Diskussionen mit Bloggern anderer Meinung auf deren Argumente ein und weichen Sie nicht durch Eröffnen laufend neuer Themen aus. Beschränken Sie sich auf eine zumutbare Anzahl von Kommentaren pro Zeit. Versuchte Majorisierung unseres Kommentarblogs, wie z.B. durch extrem häufiges Posten, permanente Wiederholungen etc. (Forentrolle) wird von uns mit Sperren beantwortet.
- Sie können anderer Meinung sein, aber vermeiden Sie persönliche Angriffe.
- Drohungen werden ernst genommen und ggf. an die Strafverfolgungsbehörden weitergegeben.
- Spam und Werbung sind im Kommentarbereich nicht erlaubt.
Diese Richtlinien sind sehr allgemein und können nicht jede mögliche Situation abdecken. Nehmen Sie deshalb bitte nicht an, dass das EIKE Management mit Ihnen übereinstimmt oder sonst Ihre Anmerkungen gutheißt. Wir behalten uns jederzeit das Recht vor, Anmerkungen zu filtern oder zu löschen oder zu bestreiten und dies ganz allein nach unserem Gutdünken. Wenn Sie finden, dass Ihre Anmerkung unpassend gefiltert wurde, schicken Sie uns bitte eine Mail über "Über Uns->Kontakt"Das Identifizieren von noch so kleinen Trends bei der „zufälligen“ Entwicklung von z.B. Aktien-Preisen ist für Anleger seit Jahrhunderten von größter Bedeutung. Unter quantitativen Portfoliomanagern und Börsenhändlern (Hedge Funds) war es schon seit den 1990er Jahren bekannt, dass die tick-by-tick Änderungen von Wertpapier- und Futurespreisen auf kleinsten Zeitskalen vom Random Walk (Wiener Prozess = Brown’sche Bewegung = normaler Diffusionsprozess) abweichen können. Zwei Verallgemeinerung des Random Walks (bei dem die Varianz der Preis-Änderungen in der Zeit linear anwächst gemäß der Efficient Market Hypothese) boten sich an: „annomale Diffusion“ bzw. fractional Brownian Motion (fBM). In beiden Fällen wächst die Varianz wie ein Potenzgesetz in der Zeit, t^(2H), wo 0<H<1 und H als Hurst-Exponent bezeichnet wird. Für H=1/2 gelangt man wieder beim Random Walk an.
Benoit Mandelbrot war seit den 1960er Jahren der Pionier der fBM schlechthin. Dass diese Methoden jetzt Einzug in die Analyse von Klima-Daten halten, war längst überfällig. Neben ihrer Anwendung im Finanzsektor wurden diese Methoden auch schon seit Jahrzehnten in der Hydrologie sowie in der Seismologie angewendet.
Zu guter letzt gibt es jedoch meines Wissens einen kleinen Wermutstropfen: die meisten Methoden (fast alle?) zum Bestimmen des Hurst-Exponenten sind mathematisch nicht rigoros, da z.B. Beweise der entsprechenden asymptotischen Eigenschaften der Schätzmethoden noch nicht erbracht worden sind und damit die angewendeten „statistischen“ Methoden die mathematische Güte von Börsen-Chartistik haben.